Podcast Insights
Many questions were asked, answered, and a variety of topics were discussed. The story just gets better. This podcast goes deep into service meshes, load generators, circuit breaker, service mesh patterns in addition to a live demo of Meshery and more. Hosted by Henrik from Perfbytes and joined by Mark, Lee Calcote from Layer5 and Mrittika Ganguli from Intel. Tune in to find out more. Get answers to all community questions as a bonus.
What is a service mesh?
Service mesh is one of the solutions that helps you to route traffic within your cluster so as to expose your services outside the cluster. It is a solution to control how different parts of an application share data with one another. Unlike other systems for managing this communication, a service mesh is a dedicated infrastructure layer built right into an app. You have different options like the service type load balancer or using ingress but service mesh makes sense because it will manage a lot of features around your service to service communication.
In general, service meshes arose from the concept of proxies such as the NGINX proxy. Then Envoy was introduced by Lyft. Lyft had the architecture, and Google came along and created it. That gave us Istio, which is now part of CNCF.
We were slugging it out in our labs trying to figure out how to do performance benchmarking with a service mesh. Instead of ten tools, if we had just one, it would be nice. Then we see Meshery come into the field
Mrittika
Service meshes, according to Lee, "hit a real sweet spot personally", having been focused on networking for most part of his career. He believes that there are a couple of different ways to speak about the genesis of service meshes, with Linkerd being the first to coin the term. We had Linkerd v1 written in scala and use jvm and then came Linkerd v2 which is something totally different at this point. It's all different code, different languages and a different service mesh architecture. There's a number of different architectures by which service meshes are deployed. There's a new one that's been softly announced in beta from called Cilium that is helping bring back some of the different architectures of how to run the proxies.
The way I prefer to think about a surface mesh is that it's all about resiliency. If you were to take a three-tiered web or three-tiered app and you think about how you're breaking out those tiers with some amount of kind of vertical scaling, you'd probably, end up putting at least a virtual IP address out in front of the whole web tier and then you've got an app tier and a database tier because you've got multiple instances of those things. Maybe there's a load balancer in between. This structure makes it simple to boost your resiliency.
Henrik goes on to elaborate that in service mesh we can do a lot of things to make sure that the communication is reliable. When you design microservice architecture, there is a need of implementing retry logic. So if a service A needs to introduce another service B, then the service mesh will manage the retry logic such that if we reach at one time and the service B is not responding then the service mesh will try to reach out several times. Therefore a service mesh offers a variety of features like this to manage the certificates within the cluster and and circle them in a regular pace. You can also have traffic splitting if you do canary releases. In your service to service communication, there are a plethora of scenarios that the service mesh can handle. Henrik recalled that it's normally difficult to obtain a full view of what rules we've applied in the cluster, and when he first saw Meshery, his immediate thought was, "Wow, this is exactly what is missing in the market at the moment."
Lets dig deeper into this tool we've been alluding to for a while now: Meshery.
Meshery
If you were on a pager and were managing a large service mesh deployment with a number of rules and configurations around how security is enforced and identities are managed, and things like uniform observability and how metrics and logs are collected and enforced, and then the different traffic writing rules and stuff. You might soil myself if you had to go make a change in that sea of yaml. That's in part what we're working towards. There's a capability within Meshery for solving this challenge. As a cloud native management plane, Meshery presides over top of 10 different types of service meshes and it also presides over kubernetes. You can run it outside of kubernetes or inside of kubernetes.Meshery has a number of components to its architecture. There is Meshery UI. It has a Mesheryctl, which is a CLI component. We have a number of service mesh adapters for each service mesh that Meshery supports.
What is the need for different adapters?
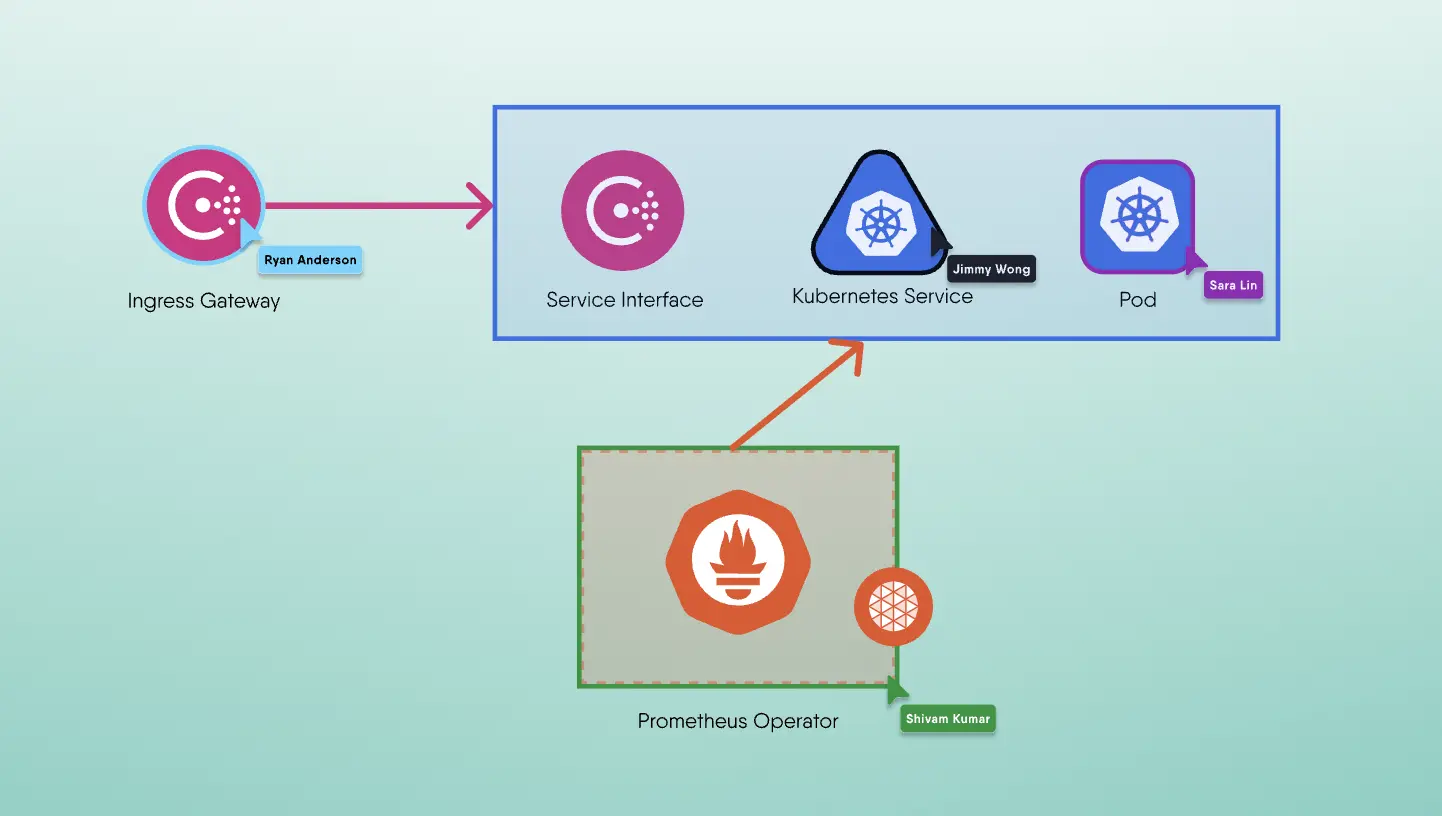
We have a plug-in for Meshery it's called MeshMap, it is what you might consider a visual topology. It has a lot of use cases for observing in kind of a read-only mode. There's a second mode to this tool: The Designer Mode. It's a visual configurator of not only the specific settings within any of those service meshes that it supports like a circuit breaker and adjusting the sensor video but also end up being a visual designer for your kubernetes deployments. When users drop in, they're able to go over and grab the specific capabilities of any of those service mesh adapters that are loaded for any of the versions of that mesh that they might want to design. The concept here is that they drag and drop these capabilities over and there's a bit of discoverability that's afforded through this ui rather than parsing through yaml, trying to understand what's going on.
I like to pretend that I know a lot about service meshes, but when it comes to having to keep track of all of them, I don't know what the gateway tls sds config is, and so this type of inline help is quite useful to design your deployments. The deployments may or may not use a mesh; in fact, you can use this to create your Kubernetes configuration and deployment as well. You can even save and recall those designs.
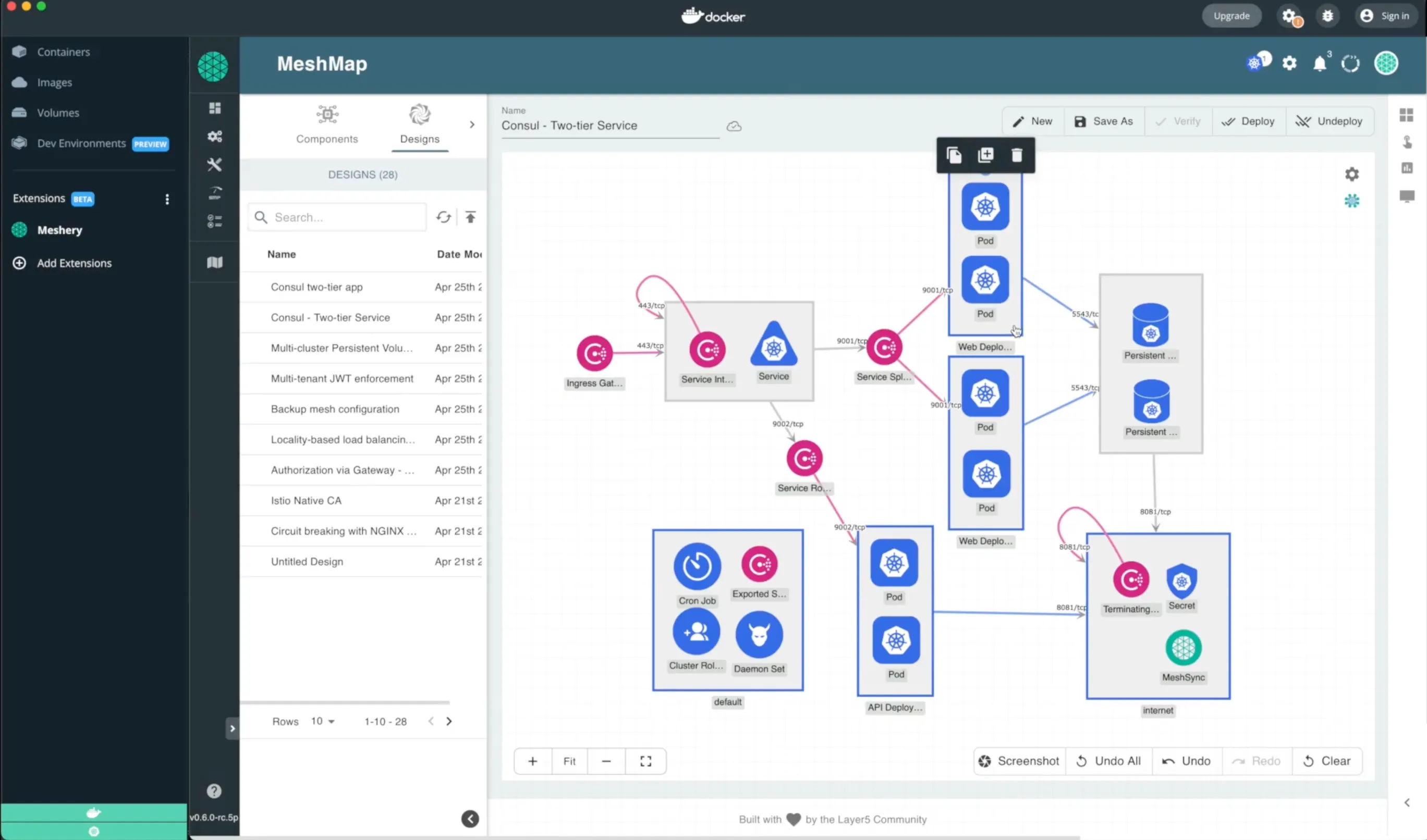
Taking this example of consul, produced by hashicorp, is a little more of an intriguing deployment and a simple two-tier deck. We announced the Meshery Docker Extension recently. So if you're using docker desktop, Meshery will be a first class app that's available inside of market and part of what it does as it integrates with docker desktop is it will import docker compose apps convert them to kubernetes manifests or kubernetes apps and they'll let you deploy those formerly docker compose apps onto a mesh which is why I'm talking about a two-tiered service.
Does MeshMap allow you to load the current configuration that is has been applied in the current cluster?
What are the capabilities of these three load generators? When you speak about service mesh testing or performance testing, what is actually the process behind the scene? What should users think about when they're starting a gig and need to configure and optimize the service mesh?
Lee expounds on that for our benefit. It takes weeks to months that you've got to dedicate for performance engineers to go over and like pull together various tools and scripts around them to then get into a spreadsheet or into some database that you then generate results. The genesis of Meshery part was to help people comprehend what a service mesh is, when to use one and which one to use? As you go to explain these common questions, the real answer is a totally disappointing, which is, it just depends on what you're asking to do.
People want to measure it in cold hard quantitative metrics but if you're asking to do 100 percent sampling then also consider the distributed tracing implementation you had somewhere else and the fact that you're getting it in a uniform way here. Maybe you're likely to consider the overhead that you would have over there. It's frustrating to be trying to explain stuff to folks and get them excited about the tech and and to give them a vague response. Instead we give them a tool that says "Hey look here's a tool that will deploy any of the service meshes that you want to test out."
There's a reason why there's ten of them like and actually many more than that. There's a lot of overlap between them but different tools for different purposes for different size orgs, so it would be inappropriate to say well you know here's the one. It's rather hey here's a tool that that lets you deploy any number of them quickly, answer your own question about performance, because we can pump out benchmarks of the various service meshes under various configurations, using different types of workloads but which may or may not match your environment and over time those reports are going to get stale and so rather he's a tool to make you empowered.
Do you actually generate traffic that will go through the sidecar proxy of the service and then reach out the actual service?
If I say I have never scripted or built any scenarios for fortio or nighthawk. Let's say I'm a loadrunner, a neoload, or a k6 user, and I want to accomplish the same thing with them. So what is the journey on those load generator? is it the same thing you have to build a workflow of requests that you want to send in that scenario?
That leads us to probably talk about one of our other projects which is called Performance which is a specification. It's another one of the projects that we've donated to the CNCF. Service Mesh Performance is the spec while Meshery is an implementation of the spec. At a high level, if those other load generators were to adhere to how we standardize and describe the test that you want to run and then hand off that configuration to generate the performance profiles that are created here you're not gonna down download them but the descriptor is important.
This implements a standard for the industry on what is the actual service mesh test and then standardize the format so then anyone can use the same format to design their script or whatever they want and then use it to test. So when I build a script, and I don't know loadrunner today and I want to use neologo tomorrow, then I don't have to rewrite everything. Great!Missed the podcast? No worries, we got you covered. Check out the recording below :)